Look Listen and Attack: Backdoor Attacks Against Video Action Recognition
Abstract
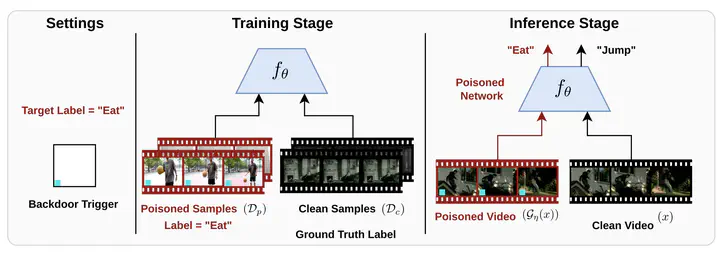
Deep neural networks (DNNs) are vulnerable to a class of attacks called “backdoor attacks,” which create an association between a backdoor trigger and a target label the attacker is interested in exploiting. A backdoored DNN performs well on clean test images yet persistently predicts an attacker-defined label for any sample in the presence of the backdoor trigger. Although backdoor attacks have been extensively studied in the image domain, there are very few works that explore such attacks in the video domain, and they tend to conclude that image backdoor attacks are less effective in the video domain. In this work, we revisit the traditional backdoor threat model and incorporate additional video-related aspects to that model. We show that poisoned-label image backdoor attacks could be extended temporally in two ways—statically and dynamically—leading to highly effective attacks in the video domain. In addition, we explore natural video backdoors to highlight the seriousness of this vulnerability in the video domain. For the first time, we study multi-modal (audiovisual) backdoor attacks against video action recognition models, demonstrating that attacking a single modality is sufficient to achieve a high attack success rate.
Hasan Abed Al Kader Hammoud
PhD Student
Hasan is an Electrical and Computer Engineering Ph.D. student in Image and Video Understanding Lab (IVUL) Group in the Artificial Intelligence Initiative (AII) at King Abdullah University of Science and Technology (KAUST) under the supervision of Professor Bernard Ghanem.